Les repères à garder en tête sur le code génétique
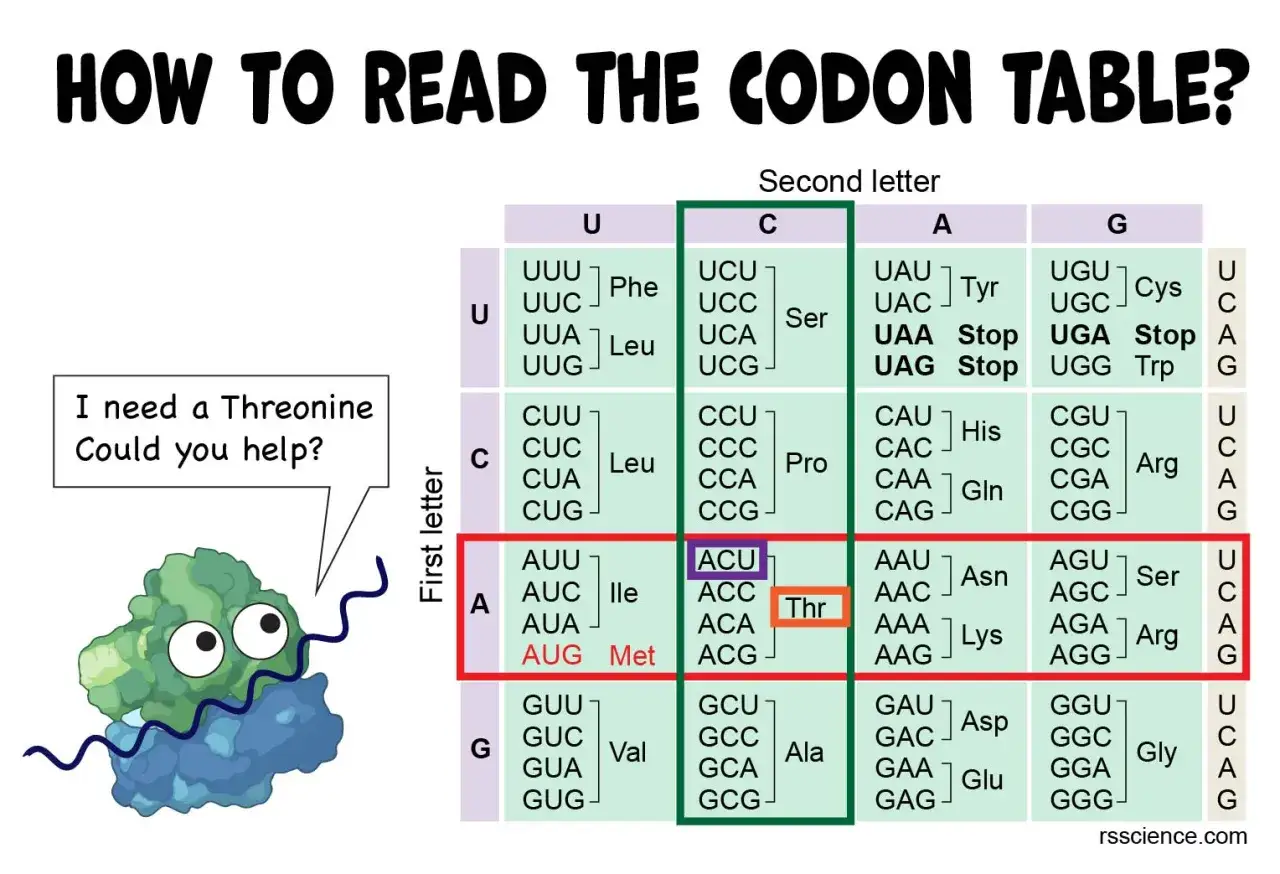
- Un codon est un triplet de bases lu sur l’ARN messager.
- Il existe 64 codons, dont 61 codent un acide aminé et 3 servent de signal d’arrêt.
- Le code est redondant : plusieurs codons peuvent conduire au même acide aminé.
- La traduction dépend du cadre de lecture ; un simple décalage change toute la protéine.
- Le code est très conservé, mais pas absolument figé : il existe des variantes, surtout dans les mitochondries.
- Son architecture s’explique par un mélange de contraintes chimiques et de pressions évolutives.
Ce que recouvre vraiment le code génétique
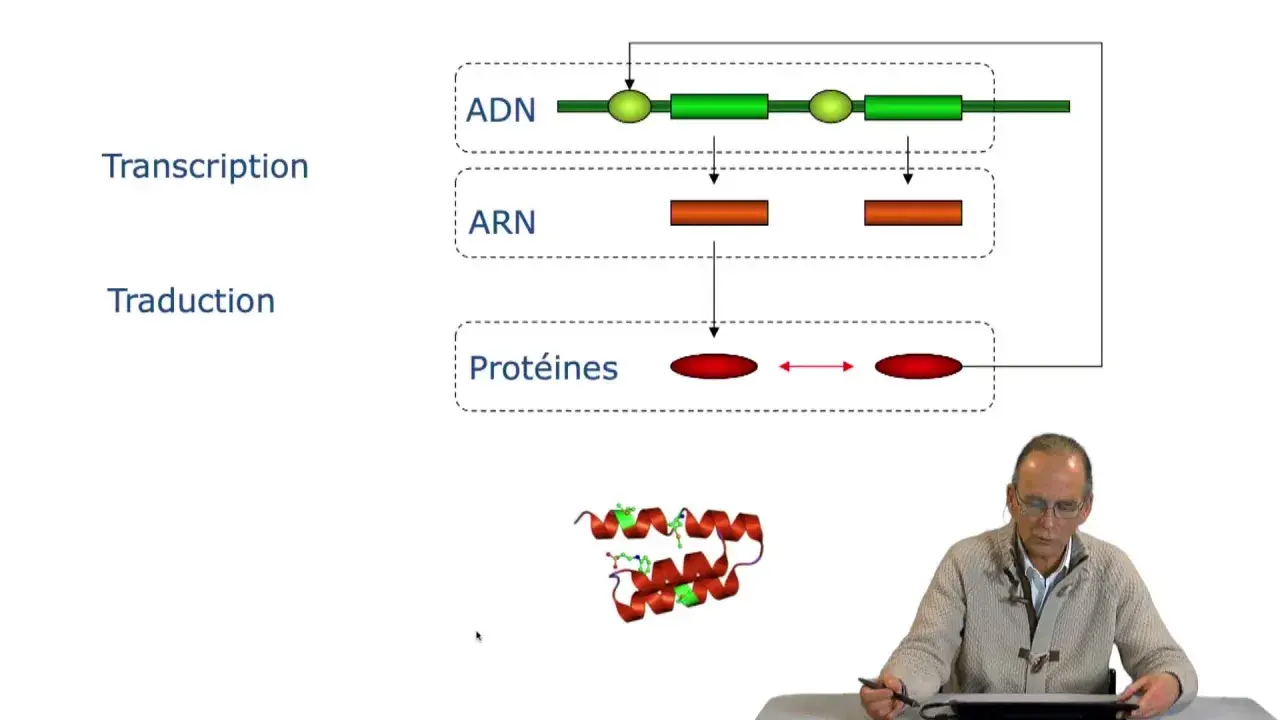
Je préfère parler d’un système de correspondance plutôt que d’une simple liste d’équivalences. Le génome stocke l’information, l’ARN messager la transporte, et le ribosome lit ce message pour assembler les acides aminés dans le bon ordre. Dans sa forme standard, ce langage repose sur quatre bases, lues par groupes de trois, ce qui donne 64 combinaisons possibles pour seulement 20 acides aminés canoniques.
| Élément | Rôle | À retenir |
|---|---|---|
| Codon | Triplet de bases sur l’ARN messager | Unité minimale de lecture |
| Acide aminé | Brique des protéines | 20 formes principales dans le code standard |
| Codon stop | Signal d’arrêt de la traduction | UAA, UAG et UGA |
| Cadre de lecture | Découpage du message par triplets | Un décalage suffit à changer tout le sens |
Cette organisation explique une propriété souvent mal comprise : le code est dégénéré, au sens biologique du terme, c’est-à-dire que plusieurs codons peuvent désigner le même acide aminé. Ce n’est pas un défaut, c’est une manière d’amortir certaines mutations. Quand plusieurs codons pointent vers la même molécule, un changement de base n’entraîne pas toujours une modification de la protéine.
Pour moi, c’est là que le sujet devient vraiment intéressant : le code n’est pas seulement une table de correspondance, c’est un filtre qui transforme un texte chimique en structure vivante. Reste à voir comment cette lecture se fait, étape par étape, dans la cellule.
Comment une suite de bases devient une protéine
La traduction repose sur une machine très précise. L’ARN messager est lu dans le sens 5’ vers 3’, et le ribosome avance par paquets de trois bases. Chaque codon appelle un ARN de transfert ou tRNA, qui porte l’acide aminé correspondant grâce à son anticodon complémentaire. En pratique, ce sont donc les tRNA qui font le lien entre le langage des nucléotides et celui des protéines.
Le rôle discret des tRNA
Les tRNA ne choisissent pas eux-mêmes le bon acide aminé : cette tâche revient aux aminoacyl-tRNA synthétases, des enzymes spécialisées qui “chargent” le bon acide aminé sur le bon tRNA. C’est un point central, et je le souligne souvent quand j’explique le sujet : sans ces enzymes, le code resterait abstrait. Elles assurent la fidélité de la traduction et limitent les erreurs de lecture.
Un exemple simple aide à comprendre la logique :
- AUG est souvent le codon de départ et code la méthionine.
- UUU code la phénylalanine.
- UGA sert généralement de signal d’arrêt.
Pourquoi le cadre de lecture compte autant
Un décalage d’une seule base suffit à bouleverser toute la suite. Si je lis AUG-GAA-UUU, j’obtiens une séquence précise d’acides aminés. Si une insertion ou une délétion déplace la lecture, les triplets suivants changent de place et la protéine produite n’a plus rien à voir avec la version initiale. C’est pour cela que certaines mutations ont des effets très lourds, même lorsqu’elles paraissent minuscules sur le papier.
Cette mécanique donne au code une grande précision, mais elle pose aussi une question naturelle : pourquoi un système aussi rigoureux admet-il des variantes, et que racontent-elles sur l’évolution du vivant ?
Pourquoi le code semble universel, mais pas figé
Dans la très grande majorité des êtres vivants, le même code relie les codons aux mêmes acides aminés. C’est l’une des raisons pour lesquelles la biologie moléculaire a pu se développer comme une science véritablement comparative. Mais “presque universel” ne veut pas dire “absolument immuable”. Certaines mitochondries, par exemple, réinterprètent des codons qui sont standards ailleurs, et quelques organismes utilisent des recodages spécialisés pour intégrer des acides aminés particuliers.| Type de situation | Ce qui change | Ce que cela montre |
|---|---|---|
| Code standard | 61 codons sens, 3 codons stop | La règle commune à la plupart du vivant |
| Variantes mitochondriales | Certains codons sont réassignés | Le code peut être modifié dans un contexte biologique particulier |
| Recodages naturels | Intégration de sélénocystéine ou de pyrrolysine | La traduction peut s’adapter à des besoins fonctionnels précis |
| Code reprogrammé en laboratoire | Réaffectation contrôlée de codons | Le code peut aussi être manipulé en biologie de synthèse |
La redondance du code contribue à cette stabilité. Des acides aminés comme la leucine, la sérine ou l’arginine disposent de six codons, alors que la méthionine et le tryptophane n’en ont qu’un seul. Cette répartition n’est pas neutre : elle influence la manière dont certaines mutations se manifestent. Une mutation silencieuse peut ne rien changer du tout, alors qu’une autre modifie légèrement l’acide aminé incorporé et peut suffire à altérer la fonction de la protéine.
Autrement dit, l’universalité du code n’est pas une rigidité absolue. C’est un compromis très robuste, qui tolère quelques ajustements sans perdre sa cohérence globale. Et c’est justement ce compromis qui ouvre la porte à la lecture évolutive du système.
Ce que l’évolution du code raconte sur les débuts du vivant
Quand on regarde le code génétique avec un œil évolutif, on voit moins un plan figé qu’un assemblage progressif. Les données actuelles suggèrent que les premiers systèmes de traduction utilisaient un ensemble plus restreint d’acides aminés, probablement dicté par leur disponibilité chimique et par des contraintes de simplicité. Certains acides aminés plus complexes semblent avoir été recrutés plus tard, au fil de l’amélioration des réseaux métaboliques et de la fidélité de traduction.
Lire aussi : Acides aminés - Briques du vivant: Comprenez leur rôle clé
Trois idées utiles pour lire cette histoire
- L’idée de “frozen accident” : une fois le code stabilisé, tout changement profond devient coûteux et rare.
- L’idée de coévolution : le code et les voies métaboliques auraient évolué ensemble, chacun influençant l’autre.
- L’idée de minimisation des erreurs : la structure du code limiterait les dégâts causés par certaines mutations ou erreurs de traduction.
Je trouve plus convaincante une lecture combinée qu’une explication unique. Les aminoacyl-tRNA synthétases, qui assurent l’attachement des bons acides aminés aux bons tRNA, semblent avoir joué un rôle majeur dans cette histoire. Leur évolution vers plus de précision a probablement permis au code de gagner en fiabilité, puis en complexité. En parallèle, les codons disponibles ont été répartis de manière à préserver au mieux la fonction des protéines malgré les mutations.
Ce point est important : le code n’est pas “parfait” au sens absolu, mais il est suffisamment robuste pour avoir accompagné l’évolution du vivant sur une immense durée. C’est cette combinaison de contrainte, de souplesse et de mémoire évolutive qui en fait un objet biologique si particulier.
Les repères qui évitent de mal lire le code génétique
Quand j’explique ce sujet, je remarque toujours les mêmes confusions. Elles sont simples à éviter, mais elles faussent vite la compréhension si on les laisse s’installer.
- Le code génétique n’est pas le génome : le premier est une règle de traduction, le second est l’ensemble de l’information héréditaire.
- Un codon n’est pas un gène : c’est seulement un triplet de bases à l’intérieur d’un message plus long.
- Une mutation silencieuse ne signifie pas “mutation sans effet” dans tous les cas : elle peut influencer la vitesse de traduction ou la stabilité de l’ARN.
- Un code “quasi universel” n’est pas un code identique partout : les exceptions existent, même si elles restent minoritaires.
- La redondance du code n’annule pas les risques biologiques : elle les amortit, elle ne les supprime pas.
Si je devais résumer l’essentiel en une phrase, je dirais ceci : le code génétique est un système de traduction très conservé, suffisamment souple pour avoir évolué, et suffisamment contraint pour rester lisible par presque toute la vie. C’est cette tension entre stabilité et adaptation qui le rend central en biologie et si riche pour comprendre l’évolution.